
Python is a pretty common choice for a lot of security specialists developing tooling due to its elegant syntax and a huge library of handy modules, packages, and libraries. Its interpreted nature means it’s flexible, has dynamic typing, easy to debug, and cross-platform. It’s arguably pretty easy to pick up as well, meaning it’s more accessible to people who aren’t pro developers.
In this blog, we will be looking at Python libraries useful for OSINT investigations. The purpose of highlighting these libraries is to show what is possible with simple Python applications. The selection of libraries highlighted here can be found in the Python Package Index with the links below.
- https://pypi.org/project/networkx/
- https://pypi.org/project/beautifulsoup4/
- https://pypi.org/project/ExifRead/
- https://pypi.org/project/ipwhois/
- https://pypi.org/project/phonenumbers/
Library 1: NetworkX
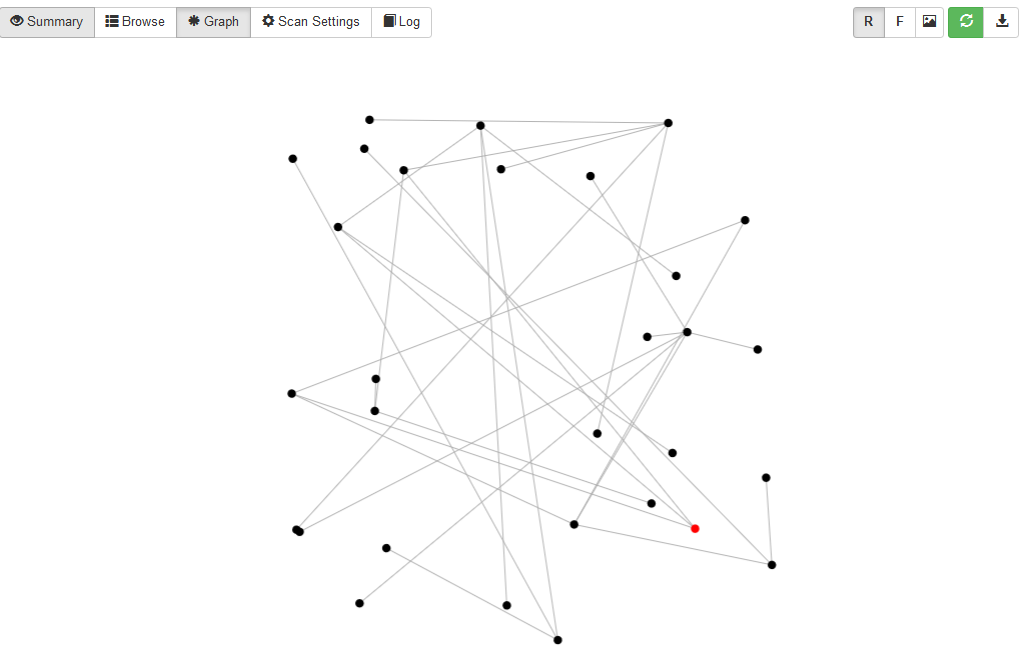
Node graphs are a useful way to visualize the relationships between information. NetworkX is a Python library that can be used to visualize networks, social graphs, infrastructure, and other data. Data in the graph is represented as vertices and relationships are represented as edges between vertices. Using the NetworkX library data can be loaded directly into a Python interpreter or via a script to build the graph, an example of a simple graph can be seen below.

Building a graph with the interpreter
>>> import networkx as nx
>>> G = nx.Graph()
>>> G.add_edge(1, 2)
>>> G.add_edge(1, 3)
>>> G.add_edge(1, 5)
>>> G.add_edge(2, 3)
>>> G.add_edge(3, 4)
>>> G.add_edge(4, 5)
>>> nx.draw(G)Although our graph here is showing simple integers it can be used to visualize much more complicated data with several different relationships. Manually building these graphs through the interpreter can be time-consuming and introduces potential errors. SpiderFoot can automatically generate these graphs from scans and help you visualize an investigation with ease. To access this feature, complete a scan and navigate to the graph page to see your results automatically visualized!
Library 2: BeautifulSoup
There are a lot of sites that offer API’s and downloadable data sets but there are still a ton of sites with useful OSINT that don’t offer these options. That’s when you’ll need to do some web scraping! If you’re reading this blog, you’ll likely know what web scraping is but if not, it’s a term for extracting out information from mostly HTML from HTTP responses.
BeautifulSoup is one of the best Python libraries for parsing HTML and XML. It makes it extremely easy to scrape information from web pages and provides “Pythonic” idioms for iterating, searching, and modifying the parse tree.
SpiderFoot uses this library in a few different modules, including:
sfp_dnsdumpster
The DNSDumpser module performs passive subdomain enumeration using dnsdumpster. BeautifulSoup is used here to extract out a CSRF token and use it for the following request where we parse the HTML and extract out subdomains from https://dnsdumpster.com :
html = BeautifulSoup(str(res2["content"]), features="lxml")
escaped_domain = re.escape(domain)
match_pattern = re.compile(r"^[\w\.-]+\." + escaped_domain + r"$")
for subdomain in html.findAll(text=match_pattern):
subdomains.add(str(subdomain).strip().lower())sfp_emailformat
This module searches the site https://www.email-format.com/ to find the email address format in use by companies. Give this module a domain name and it will (hopefully) return email addresses from the given domain. BeautifulSoup is used in this module to parse the response data, extract the table body out to then pass it to our custom parseEmails function.
html = BeautifulSoup(res["content"], features="lxml")
if not html:
return
tbody = html.find('tbody')
if tbody:
data = str(tbody.contents)
else:
# fall back to raw page contents
data = res["content"]
emails = self.sf.parseEmails(data)sfp_reversewhois
Reversewhois.io is a search engine used to find domain names owned by an individual or a company. Simply provide a domain name to this module and it should return any affiliated domains, as well as domain registrar information. BeautifulSoup here parses the response data and iterates through all of the rows in the HTML table to extract out the Reverse Whois information on the provided domain. You can see the full module code here.
html = BeautifulSoup(res["content"], features="lxml")
date_regex = re.compile(r'\d{4}-\d{2}-\d{2}')
registrars = set()
domains = set()
for table_row in html.findAll("tr"):
table_cells = table_row.findAll("td")
# make double-sure we're in the right table by checking the date field
try:
if date_regex.match(table_cells[2].text.strip()):
domain = table_cells[1].text.strip().lower()
registrar = table_cells[-1].text.strip()
if domain:
domains.add(domain)
if registrar:
registrars.add(registrar)
except IndexError:
self.debug(f"Invalid row {table_row}")
continue
ret = (list(domains), list(registrars))
if not registrars and not domains:
self.info(f"No ReverseWhois info found for {qry}")Library 3: Exifread
Exif (Exchangeable image file) data contains information on media captured by digital cameras, scanners, and other systems that handle image and sound files. It can be very useful for OSINT investigations as it often describes geolocation data and when the picture was taken.
Exifread is a simple python library used to extract Exif data from image files. SpiderFoot uses it in the “sfp_filemeta” module to extract out the metadata from jpg, jpeg, and tiff files. By providing a link or an interesting file, this module will return the metadata and any software used.
if fileExt.lower() in ["jpg", "jpeg", "tiff"]:
try:
raw = io.BytesIO(ret['content'])
data = exifread.process_file(raw)
if data is None or len(data) == 0:
continue
meta = str(data)
except Exception as e:
self.error(f"Unable to parse meta data from {eventData} ({e})")
returnLibrary 4: IPwhois
IPWHOIS.io provides fast and versatile whois information for IPv4 and IPv6 addresses. OSINT you can gather from a WHOIS lookup includes geolocation Data, ASN Information, and details on the organization that owns the IP. SpiderFoot uses this library in our aptly named sfp_whois module to provide domain registrar information. As you can see from the below code snippet, it’s very simple to use:
try:
<code> r = ipwhois.IPWhois(ip)
data = str(r.lookup_rdap(depth=1))
except Exception as e:
self.error(f"Unable to perform WHOIS query on {ip}: {e}")</code>
Here you can see the creation of the domain registrar SpiderFoot event, created from the WHOIS data:
if eventName.startswith("DOMAIN_NAME"):
if whoisdata:
registrar = whoisdata.get('registrar')
if registrar:
evt = SpiderFootEvent("DOMAIN_REGISTRAR", registrar, self.name, event)
self.notifyListeners(evt)Library 5: Phone numbers
Phone numbers can be used to collect clues on the owner’s identity and reveal connected accounts and other information tied to a phone number. Phonenumbers is a Python library that provides basic information on a phone number, including validation, country code, carrier information, timezone, and the ability to extract phone numbers out of text.
It’s very simple to use the library, with a few different features. Here’s an example of using the interpreter to obtain carrier information:
>>> import phonenumbers
>>> from phonenumbers import carrier
>>> number = phonenumbers.parse("redacted")
>>> carrier = carrier.name_for_number(number, 'en')
>>> print(carrier)
OptusThe Phonenumbers library is used in two modules from SpiderFoot:
sfp_countryname
This module aims to identify the country related to a variety of data you can provide, such as phone numbers, domain names, IBAN numbers, Geographic info and physical addresses. The detectCountryFromPhone function contains an example of how to use this library to obtain the related country from a phone number:
def detectCountryFromPhone(self, srcPhoneNumber):
"""Lookup name of country from phone number region code.
Args:
srcPhoneNumber (str): phone number
Returns:
str: country name
"""
if not isinstance(srcPhoneNumber, str):
return None
try:
phoneNumber = phonenumbers.parse(srcPhoneNumber)
except Exception:
self.debug(f"Skipped invalid phone number: {srcPhoneNumber}")
return None
try:
countryCode = region_code_for_country_code(phoneNumber.country_code)
except Exception:
self.debug(f"Lookup of region code failed for phone number: {srcPhoneNumber}")
return None
if not countryCode:
return None
return self.sf.countryNameFromCountryCode(countryCode.upper())sfp_phone
The purpose of this module is to extract out phone numbers from scraped pages and provide carrier information. You can pass this module web content, domain, and netblock whois information, as well as a phone number. Here’s a code snippet demonstrating how SpiderFoot parses a phone number and retrieves carrier information:
if eventName == 'PHONE_NUMBER':
try:
number = phonenumbers.parse(eventData)
except Exception as e:
self.debug(f"Error parsing phone number: {e}")
return
try:
number_carrier = carrier.name_for_number(number, 'en')
except Exception as e:
self.debug(f"Error retrieving phone number carrier: {e}")
return
if not number_carrier:
self.debug(f"No carrier information found for {eventData}")
returnWrapping up
Python has been around for more than 30 years and in that time it has built a strong following of software developers, data scientists, security professionals, and OSINT investigators. The wealth of modules you can use to investigate makes knowing how to read and write Python one of the most valuable skills in the OSINT investigator’s toolkit. We’ve explored how SpiderFoot uses Python to automate investigations to speed up information gathering from many different sources and how the platform combines them into an easy-to-use tool for OSINT investigations.
Leveraging automation when performing investigations is crucial to make sure you cover as much ground as possible, as quickly as possible. However, speed isn’t the only important factor, being able to modify, explore and expand your tooling is a great advantage. SpiderFoot is an open-source project so you can pour over the code to learn how it uses common Python packages to search for information.
You can also extend SpiderFoot’s functionality to cover nearly every OSINT use case you could imagine. If you find one we haven’t covered yet, feel free to create a new module and submit a pull request to the Github repo.
Thanks for following along with this blog, we hope you’ve learned something new!




