
Before busting out your arsenal of tools to rip a website apart, it can be really useful to just go back to basics and start by simply making a request to the website and analyzing its response. This applies to beginners as well; before learning all of the different tools and commands it’s important to understand the basics. Web servers will often happily give away sensitive OSINT, perfect for your recon or investigation. This lesson will cover all the juicy information you can get from a simple request.
HTTP Requests
There are several types of requests that can be used with HTTP servers on the Internet, the simplest and most frequently used is the GET request. This request type asks a server for some data located at an endpoint and often returns a wealth of information. Various tools can be used to make requests to servers; these include Internet browsers, command-line interfaces, and graphical suites that include other tools for debugging and testing web applications. We’ll look more into these tools later, but we can use the popular and ubiquitous cURL command built into most Linux distributions for now.
An HTTP request has two main parts, a request and a response. The request to the site needs an address to send the request to and the type of request; this can be GET, POST, UPDATE, DELETE, or a handful of other (mostly irrelevant) request types. The response is a set of data returned to the client, it contains several parts, and in the next section, we will look into a couple of these to find out more information about an application.

Request Headers
Let’s begin with HTTP headers; these are metadata fields that both the client and server exchange to communicate how the client wants to receive data and how the server can respond. The client header’s main purpose is to describe the client to the server so that the client receives the best possible version of the content they are requesting. Below we can see what information is described in the request headers.
- Who: authorization headers tell the server that the user wants to identify themselves with a set of credentials; these are used to login to services. These can be simple username/password combinations or more advanced tokens like JWT or OAUTH.
- What: user agents tell the server what client the user is requesting information from. A server can respond differently by providing a mobile version if the user connects with their phone using this information.
- Where: IP address also tells a server a little about who is connecting; they can provide a somewhat accurate geographic location and information about what network a user is connecting through, such as a cellular network or broadband. This information can be used to serve localized content and reduce latency by using a geographically closer server. Client addresses aren’t always accurate. Due to several factors such as network address translation (NAT), carrier-grade NAT, and VPNs, IPs can be shared by several devices or entire networks simultaneously.
Response Headers
How a server responds to a request can tell the client several things about how the server operates. Similar to the request headers, there is a base set of information gained by inspecting the response headers.
- What: When a server responds to a request, it will usually respond with an HTML website that explains what the server’s purpose is. Additionally, a server or X-Powered-By header tells the user what kind of server responds to their request, i.e., Apache, Nginx, .NET, etc. Similar, provider-specific headers identify CDNs or proxies such as the CF-Ray header for websites served from Cloudflare.
- Who: A server, in most cases, identifies itself by a domain name that is registered with an authority that stores information about the owner or at least the registrar that the owner purchased the domain through. A WHOIS search might reveal a website owner’s email address, physical address, name, and phone number in some cases.
- Where: Exactly like the client’s IP address, a server’s IP address can reveal where the server is physically located. Server IP addresses can be far more ambiguous than client addresses due to NAT, CGNAT, proxies, CDNs, and accelerator networks that change the actual server IP address along their path to the client.
For example, we will look at the Buggy Web App (http://www.itsecgames.com/) built by Malik Mesellem. When we inspect the returned headers, we can see that the server identifies itself through the Server and X-Powered-By headers, revealing that the server operating system is Ubuntu, the application is built in PHP and served by Apache webserver.
| Server | Apache/2.4.7 (Ubuntu) |
| X-Powered-By | PHP/5.5.9-1ubuntu4.22 |
Debug Information
Most web frameworks have some form of debugging mode intended for developers to use while they build their sites and then disabled when the sites go live. This change can sometimes be overlooked when applications are deployed quickly and can cause significant security risks. From an OSINT perspective, this data is golden! Not only does it display exact details about specific versions of software and libraries, but it also can display additional configurations that developers may have made to the application.
Debug Pages
In the last section, we determined that the Buggy Web App is built in PHP and served by Apache. We can use a simple get request to find out more about this site by displaying the PHP debug page at /phpinfo.php. The page contains details on the PHP and associated libraries’ configuration. Other frameworks can have debug pages at different locations that display similar information.
Stack Traces
Applications running in debug mode can also display very detailed messages when encountering an error called stack traces. They usually show where the error occurred in the code and a tree of execution that led to the error being thrown. What you might find in a stack trace varies from app to app, but they often include helpful information on how the application is built. One quick and dirty way to check if this functionality is enabled is by requesting a page with a different HTTP method such as POST or PATCH. Usually, pages are set up to only communicate with a specific set of HTTP methods. The framework will notice you aren’t using the correct method and throw an error. This doesn’t work in every scenario but is certainly worth trying.
Domain Name System and Nameservers
As briefly mentioned in the response headers sections, most websites on the internet use a domain name to identify themselves instead of using their IP address. The system that facilitates this translation from domains into IP addresses is the Domain Name System (DNS). DNS is a core part of the internet and contains a fair amount of information about websites and their owners. This section will explore what helpful information you could find.
Nameservers
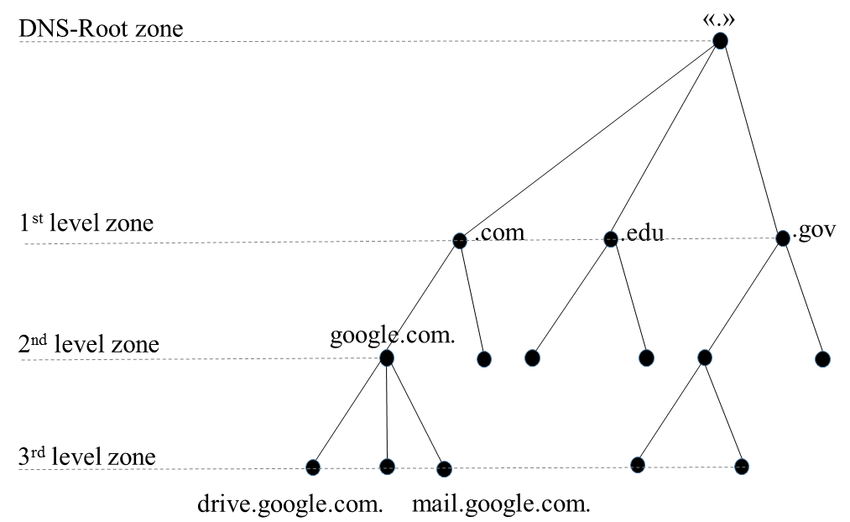
There are only two kinds of nameservers, authoritative and root nameservers. A root server controls a Top Level Domain (TLD), the suffix in a standard URL such as .com or .net. Authoritative name servers are responsible for resolving the URL’s prefix, such as google.com and mail.google.com. Below is a diagram that shows this more clearly.
DNS Queries
A record such as mail.google.com will automatically resolve to a server’s IP address during an HTTP request. We can manually resolve this record using the dig command to determine what the IP address is mapped to. This will often be a proxy of some sort or a CDN server for larger websites.
Dig can also retrieve other records than A records that point a domain name to an IP address. Querying a server’s SOA records will show the nameservers controlling the DNS for a domain. These SOA records can often tell you what hosting service a site uses if IP results aren’t enough.
For our Buggy Web App, I have hosted it in AWS but using Cloudflare for CDN. When I check the IP address A record I can see that it points to a Cloudflare IP address. To determine the hosting provider, I can check the SOA record and see that AWS nameservers are present.
MX records can be resolved to determine if a domain name is also set up for email services. We may be able to tell from this record other associated TXT records where the email server is hosted and what technologies it uses.
API Calls
More complex websites will utilize several APIs to provide everything from authentication services to image resizing. From loading a webpage and viewing the additional calls a site makes, we can discover what internal and external services a site uses.
Internal Calls
Calls to internal services are commonly used for website functionality and authentication. A typical example from Twitter is the internal video API that returns a video file attached to a post.
Another example is the API request when a user likes a post or comments. These internal API calls can reveal other domains owned by a service or give insight into how a service works.
External Calls
Commonly, websites will utilize functionality built by other services instead of building it themselves. An excellent example of this is analytics services. Tracking users across the web is a challenging functionality to build yourself. Large analytics platforms like Facebook and Google provide these services as an external API that sites use to track visitors and purchases. These calls can be seen if you inspect the request flow on a website. Another example is Single Sign On (SSO), which allows a user to log in to multiple websites with a single account and makes extensive use of external API calls.
Technology Stack
Finding information on a web app’s technology stack tends to be a fairly easy task. Applications will often explicitly tell you what frameworks they’re using in HTTP headers like the “x-powered-by” field in the example we had above. Additionally, server information can be found in the aptly named “server” HTTP header. Often you’ll come across web applications that do not respond with identifying HTTP headers but nonetheless, framework fingerprinting can still be done through;
Cookies
Some frameworks will come with framework-specific cookies. If the developer hasn’t changed the configurations affecting the cookies, you can use them to identify the underlying technology. For example, Django CMS has an identifying cookie called “django” and Laravel can be identified through the “laravel_session” cookie.
HTML Source Code
Examining the “<head>” and “<meta>” tags in the HTML source code may give you clues on the underlying framework and components. Additionally, comments, script variables, and paths will provide helpful clues.
Folder Paths and Files
Some frameworks will reveal themselves through their directory structure and files. For example, you can quickly identify a WordPress site through folders prefixed with “wp”. For example, “/wp-admin/” and ”/wp-content”.
File extensions
Frameworks can be easily identified through file extensions. If you see a filename with a “.php” extension, you can safely assume that the web application is written in PHP.
Error Messages
As we spoke about in the “Debug Information” section, error messages will often indicate underlying technology.
Third-Party Storage
Third-party storage such as Amazon’s S3 Buckets, Azure’s Blob Storage, or Google Clouds Storage buckets will often be revealed through GET requests. When browsing a site, keep your proxy on and notice where assets are coming from, you might notice a third-party storage URL. It’s worth checking if public access is enabled on the bucket, there might be some sensitive information in there!
Analytic IDs
Did you know you can use analytic IDs to identify related websites? You can find analytic IDs by looking at the HTML source code. For example, you can find the google analytic ID by searching for “UA-”. A lot of companies will use one analytic ID across multiple domains to track user activity. The last digit of the google analytic ID will indicate how many domains are using the ID. For example, “UA -12345678 -9” indicates that the analytic ID is being used across 9 sites. You can search tools like censys or SpyOnWeb for “UA-123456789” to see what other websites are using the same analytic ID. Both of these tools are integrated into SpiderFoot!
Company and Personal Information
A variety of OSINT around people and companies can be scraped from websites using a single request, such as:
- Email Addresses
- Peoples Names
- Cryptocurrency wallets
- Phone Numbers
- Usernames
- Physical Addresses
- Hostnames
A really simple way to quickly extract some of this information is to combine curl with grep using regex. For example, to extract phone numbers from a site you can use this simple command:
curl -s https://www.spiderfoot.net | grep -E -o "^(\+\d{1,2}\s?)?1?\-?\.?\s?\(?\d{3}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"Using these noninvasive techniques can be extremely valuable in situations where you don’t want your target to know they’re being investigated, or perhaps you’re looking at a sensitive application in an OT environment where you don’t want to spam the application with too many requests. In these situations, you can also use SpiderFoot in “Passive” mode to gather information without sending out a barrage of requests!
SpiderFoot
You can scrape all of these details from a website manually, but it ends up being quite time consuming and error prone. An excellent alternative is to use SpiderFoot. SpiderFoot has modules to scrape all of the data types mentioned above, quickly and automatically! Check out the self-hosted, free, open source version here, or our premium, hosted version here!




